







在 AI 语音合成(TTS)领域,Index-TTS 以其高度的真实感和灵活性,成为了许多开发者和内容创作者的首选工具。然而,部署高性能的 TTS 模型往往需要依赖强大的本地 GPU 资源,这对于没有专业硬件的用户来说是一个不小的门槛。本文提供一个极具成本效益和高效性的解决方案:利用 Google Colaboratory (Colab) 的免费或付费云端 GPU 资源,搭建一个稳定、可远程访问的 Index-TTS API 服务。 无论是 Index TTS 2.0 或者是 Z-image,都可以基于这样的方案在一定程度上摆脱本地配置,拥有一个随时随地可调用、为应用程序或网站提供非实时语音合成能力的在线 API 接口。
准备工作
- 一个 Google 账号:Google Colab、Google Drive 在本例中都需要使用,将在 Google Colab 中挂载、使用 Google Drive
- 一个 Ngrok 账号:用于内网穿透、提供公网可访问的 url 链接。尽管 Gradio 库提供了同类功能,但在并不需要 WebUI 界面的前提下,建议使用 ngrok 或 cloudflare tunnel。
注册 ngrok 获取 Token
在 ngrok 官网,点击右上方『Sign up』注册一个账号,详细过程不做描述,可以使用 google、github 账号进行关联注册,也可以使用邮件进行注册。
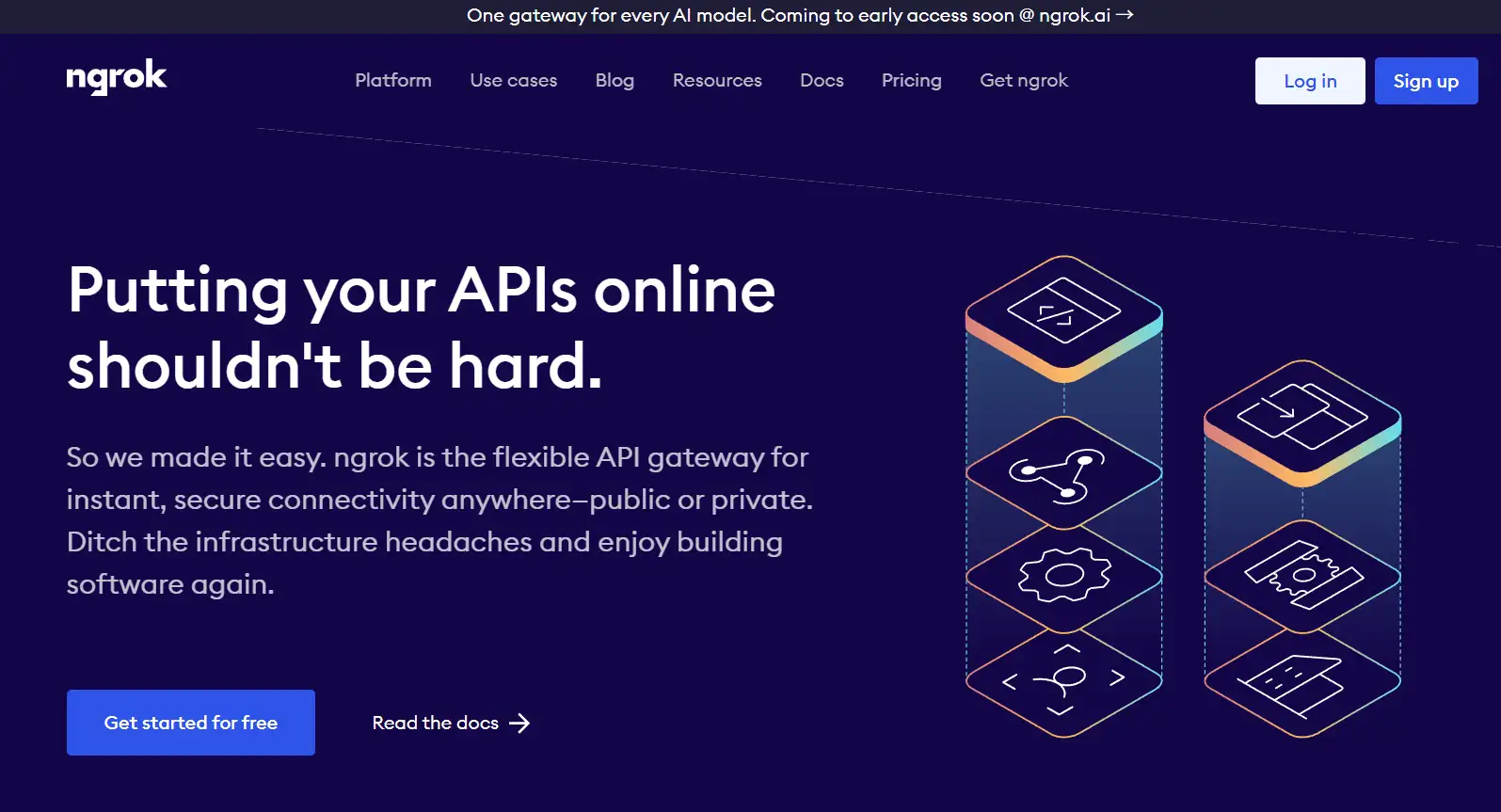
注册完成后,点击左侧导航栏的『Your Authtoken』,然后点击 Copy 就可以将专属的 TOKEN 拷贝备用。我们需要将笔记本中参数值修改为自己获取的 TOKEN。
加载笔记本并配置环境
首先,点击在 Colab 中打开 ![]() 。或者,点击「这里」下载后在上传到 Google Drive,然后双击打开即可。
。或者,点击「这里」下载后在上传到 Google Drive,然后双击打开即可。

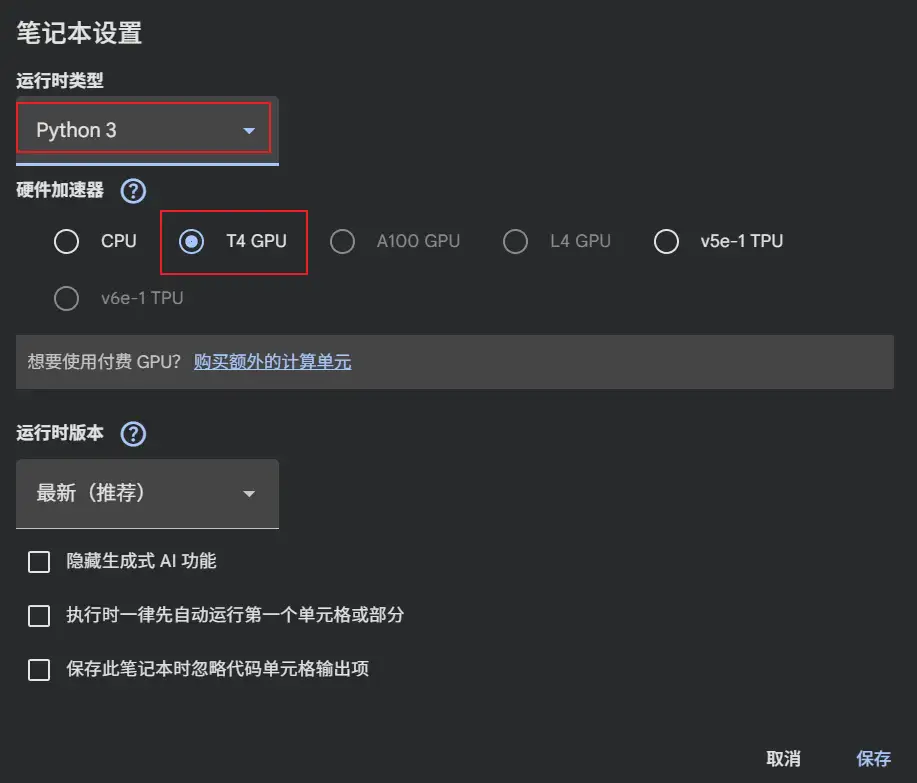
打开后,我们点击顶部左上侧的『修改』菜单,选择『笔记本设置』。
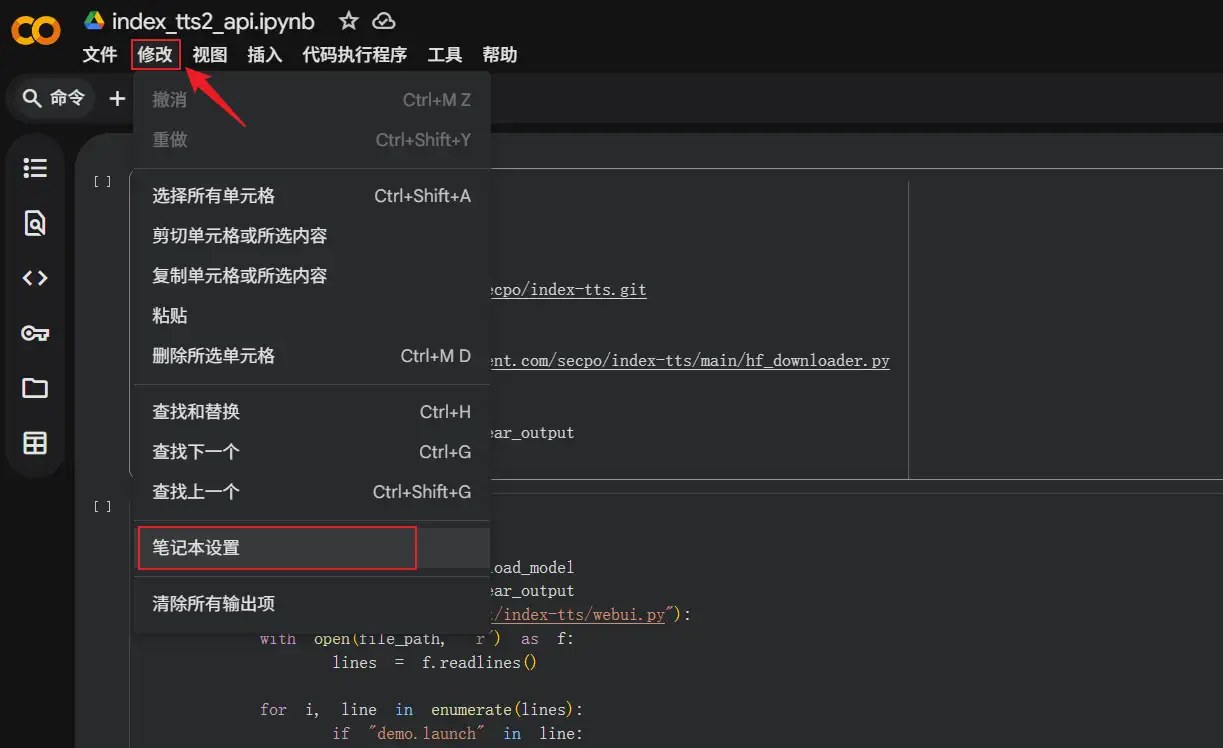
或者,点开右上侧的三角符号,选择『更改运行时类型』。
在打开的模态对话框中,选择 Python 3,以及 T4 GPU。然后,点击保存即可。
加载 Index-TTS 后台服务
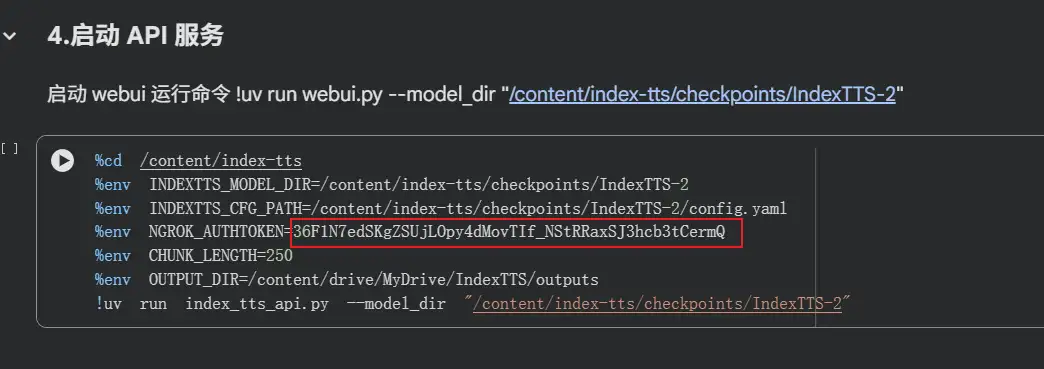
在开始运行代码之前,务必修改最后一个单元格中的 NGROK_AUTHTOKEN 为前序步骤获取并拷贝的。
接下来,就可以点击『全部运行』顺序执行所有单元格的代码了。
在单元格执行过程中,需要特别注意以下几点:
- Google Colab 运行时的根目录为 /content
- 音色文件:不宜过长,10-15 秒即可
- Google Drive 挂载:第三个单元格执行时可能需要手动授权,Google 云端硬盘的根目录挂载后的路径是 /content/drive/MyDrive
- Ngrok 生效:所有单元格运行完成后,如果是首次使用 ngrok,应点击打印输出的 ngrok 公网链接,跳转打开 404 页面说明隧道已经建立、内网穿透正常
如何在客户端使用
示例命令行
curl -X POST \ -F "voice_path=/path/on/server/to/voice_prompt.wav" \ -F "file=@/path/on/your/local/machine/input.txt" \ https://uncommunicatively-spirochetotic-yetta.ngrok-free.dev/api/synthesize
参数解释
- -X POST : 指定使用 POST 方法发送请求。
- - F "voice_path=/path/on/server/to/voice_prompt.wav" ,参数指定了用作语音参考的音色文件。(重要提示: 这里的路径是 API 服务器上 的文件路径,而不是从本地计算机上传指定的路径。例如,在 Colab 环境中,可能是 /content/drive/MyDrive/sample.wav 等,表示 google drive 根目录下的 sample.wav 音色文件)
- - F "file=@/path/on/your/local/machine/input.txt",用于上传包含待合成文本的 .txt 文件。(提示: @ 符号表示这是一个文件上传。这里的路径是运行 curl 命令的本地计算机 上的文件路径,将其替换为实际文件路径,如 D:\texts\my_story.txt 或者 input.txt )
- - https://uncommunicatively-spirochetotic-yetta.ngrok-free.dev/api/synthesize,API 的完整公网接口地址
在远程客户端输入命令后,通过 API 调用,将包含所有待合成内容的文本文件上传后,我们会在 colab 中观察到后台的推理作业输出。同时,示例 api 不会向客户端反馈任何信息,也就是说,在后台开始工作后是可以关闭客户端命令行窗口的。
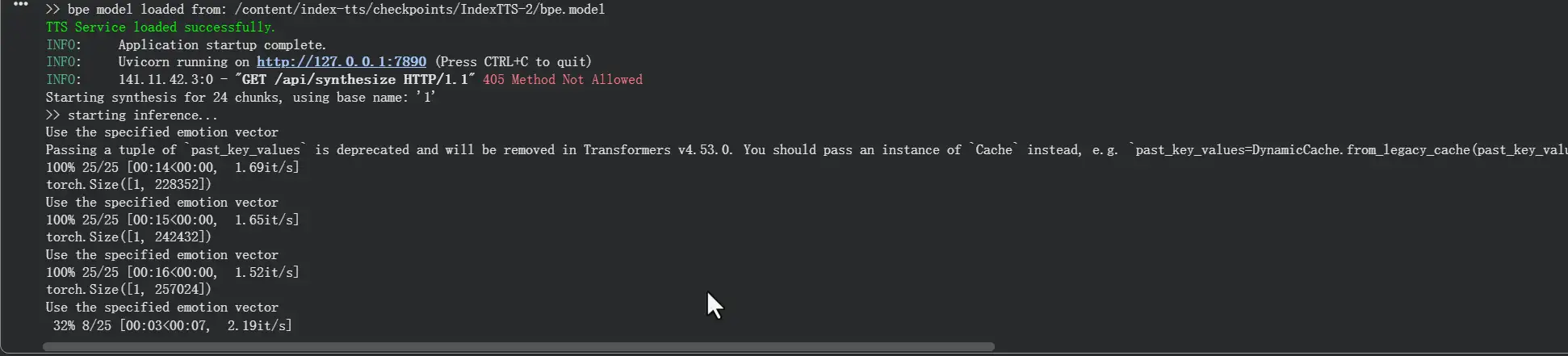
推理结果输出
示例 api 会固定将过程文件(每个分段的合成音频)和最终的音频文件输出到 Google Drive 根目录的 Index-TTS/outputs 下,对字数并不设限,理论上可以支持 10000 字的长文本 TTS 转录,但考虑到 T4 GPU 在不开启所有优化参数的前提下 RTF >3 ,长文本转录会非常耗时。一旦 Google Colab 抢占(持续推理 1 小时以上)GPU 资源或中断会话,就需要手动从中断处继续转录。
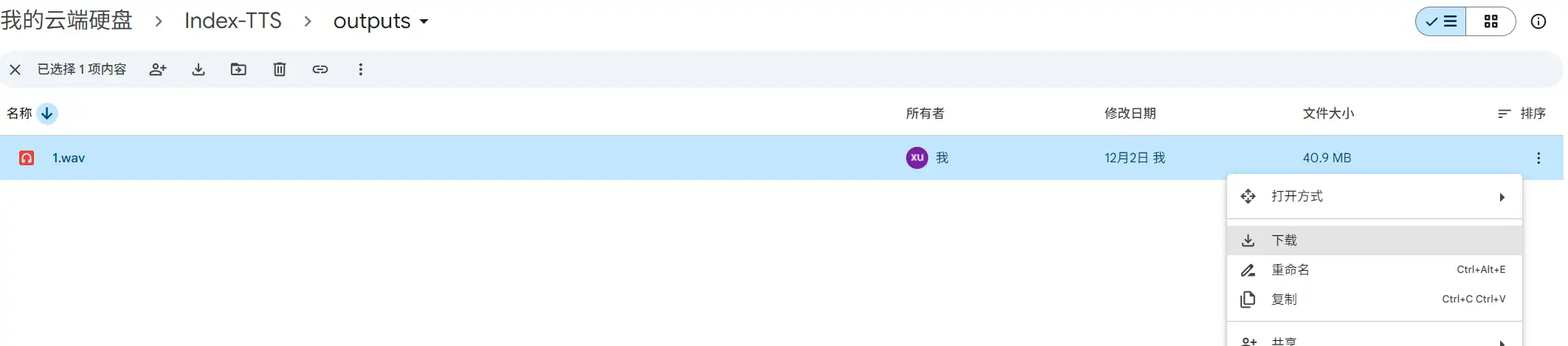
同样,示例 api 对于音色文件也采用固定路径和文件名(/content/drive/MyDrive/Index-TTS/samples/1.wav),生产应用中一旦选定了音色,一般不需要进行频繁修改。如果转用 Kaggle 平台,默认单 T4 在不开启优化的前提下 RTF 一致,双 GPU 并行处理时,RTF 为 1.5 ~ 2,每周 30 小时配额,可合成至少 15 小时音频,播客(Podcast)等非实时场景完全可用。
如果需要通过 webui 进行语音合成并且使用 Index TTS 丰富的推理参数配置,可以将最后一行的单元格代码修改为 !uv run webui.py --model_dir "/content/index-tts/checkpoints/IndexTTS-2",基于 Gradio 的 webui 正常运行所需要的公网访问参数,已在前序单元格配置好。
%cd /content/index-tts %env INDEXTTS_MODEL_DIR=/content/index-tts/checkpoints/IndexTTS-2 %env INDEXTTS_CFG_PATH=/content/index-tts/checkpoints/IndexTTS-2/config.yaml %env NGROK_AUTHTOKEN=36F1N7edSKgZSUjLOpy4dMovTIf_NStRRaxSJ3hcb3tCermQ %env CHUNK_LENGTH=250 %env OUTPUT_DIR=/content/drive/MyDrive/IndexTTS/outputs !uv run index_tts_api.py --model_dir "/content/index-tts/checkpoints/IndexTTS-2"
结语:释放 AI 语音的无限潜力
通过本文提供的基于 Google Colab 和 Ngrok 的部署方案,可以成功打破了高性能 Index-TTS 模型对本地专业硬件的依赖。现在,在一个高性价比、可远程访问的 AI 语音合成 API 接口基础上,无论是 Index-TTS 2.0 还是其他基于此框架的模型,都能随时随地为应用程序、网站或播客项目提供非实时、高度逼真的语音合成服务。该方案不仅是应对资源限制的高效解决方案,更代表了 AI 部署的未来趋势:云端化、轻量化、触手可及。利用 Colab 的 T4 GPU 算力,结合 Ngrok 的稳定内网穿透,您让文本以动听、真实的 AI 声音呈现!
更多精彩,敬请关注「老 E 的博客」!





文章评论