







前段时间字节正式发布了文生图 SDXL-Lightning 微调模型, 采用了新的渐进式对抗蒸馏(Progressive Adversarial Distillation)技术,能将计算时间和成本降至此前的十分之一,SDXL-Lightning 能提速 10 倍在 2~4 步内生成高质量及高分辨率的图像。SDXL-Lightning demo 是基于 ComfyUI,但实际上同样支持 SD WebUI。本文介绍 SDXL-Lightning 快速生成 1024 高清大图的本地实现方法,体验其超出 SDXL-Turbo 和 LCM 的效果以及在 ComfyUI 中的自建 workflow 的步骤和方法。
SDXL-Lightening简介
SDXL-Lightning 是一个由 ByteDance(字节跳动) 开发的文生图微调模型,其主要贡献在于其高速的生成能力和轻量化的设计,有关模型和论文也都已经开源。
论文:SDXL-Lightning: Progressive Adversarial Diffusion Distillation
模型:huggingface.co/ByteDance/SDXL-Lightning
本站下载传送门:「ComfyUI -cu121」 「SDXL-Lightning-2step-Model」 「SDXL-Lightning-4step-Model 」 「Workflow」
当前,SDXL-Lightning 提供了 1步、2步、4步和8步的蒸馏模型和 2步、4步和8步 的 Lora 模型(类似LCM),官方 demo 对比见下图。SDXL-Lightning 1、2、4、8步都能表现的非常好,SDXL 则中规中矩,需要 32 步才能完成,而 Turbo 和 LCM 在1步的时候表现的不太稳定,且只能生成 512*512 分辨率的图。

本地部署
首先在「ComfyUI仓库」下载最新的 ComfyUI 包,分为 cuda 118 和 121 不同的版本。结合自身 nvidia cuda 版本下载后解压。
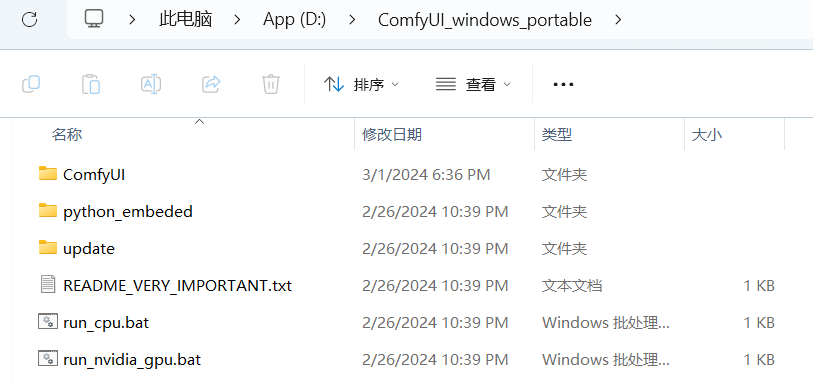
在「sdxl-lightning官方发布页」,点开「files and versions」就可以下载 1、2、4、8 微调模型或 lora 模型。这里建议下载 all in one 版本,也就是名称为 sdxl_lightning_Nstep.safetensors 的文件。

如下图选择即可,可以都下载,也可以仅下载一个对应步数的模型。本文以 4 步模型为例。
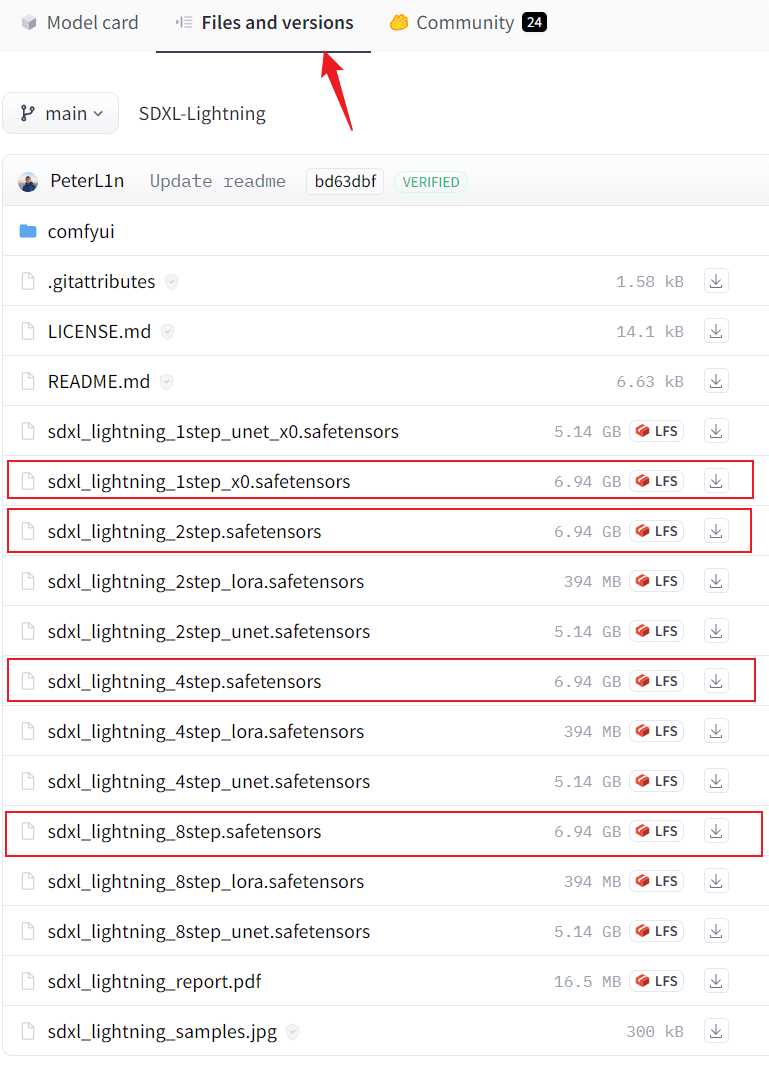
同时下载官方制作好的 wokflow 文件,默认下载 sdxl_lightning_workflow_full.json 即可,需要尝试1步出图的话可以下载 sdxl_lightning_workflow_full_1step.json
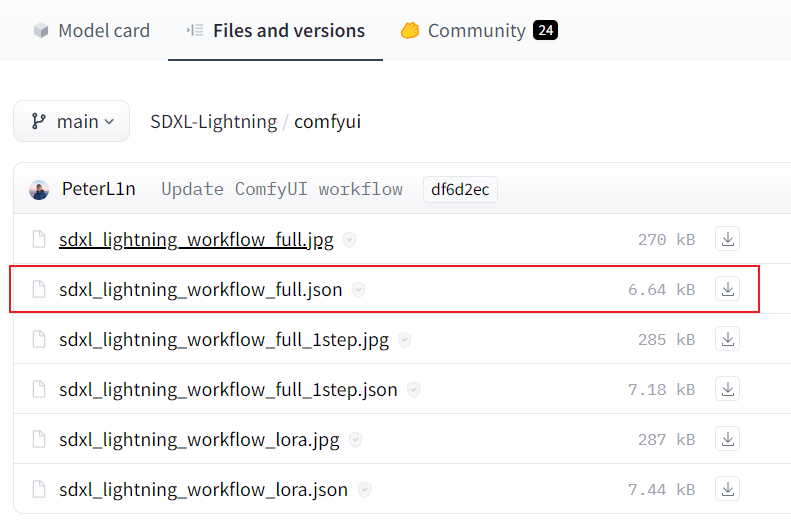
官方发布的模型默认基于 ComfyUI,模型下载解压后将模型、workflow文件拷贝入 models下checkpoints 目录中。其中,workflow 文件也可以放在其他目录,打开 ComfyUI web界面后后手动加载load ,和标准模型放在 checkpoints 同一文件夹下可以自动加载。
SDXL-Lightning绘图
双击运行 ComfyUI 下的 run_nvidia_gpu.bat 即可开始使用GPU 文生图,如果使用 CPU,则双击运行 run_cpu.bat。
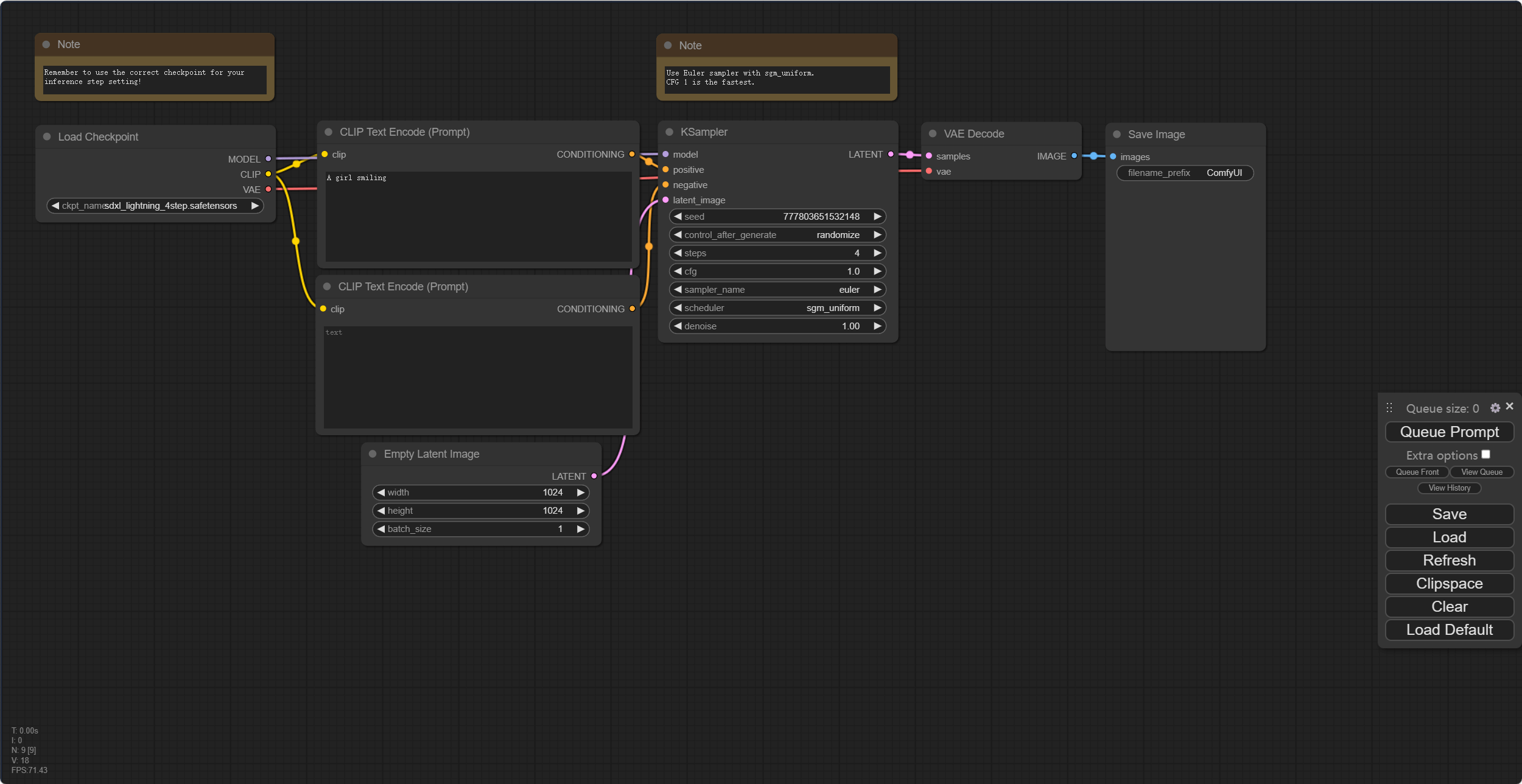
打开 sdxl-lightning 默认的workflow 界面后,直接点击「Queue Prompt」,就会采用默认填写的 “a girl smiling” 生成一张 1024*1024 的图像。即便采用4步模型,也确实比使用标准 sdxl 模型快。
提示词可以参考已有的大量的SD提示词公开库,也可以由ChatGPT生成,例如参考使用如下ChatGPT生成的提示词生成本文的 4 张1366 * 768 封面图。
**Prompt:** Stable Diffusion model,SDXL-Lightning,displayed prominently,running fast,depicting lightning,technical aspect-(best quality,4k,8k,highres,masterpiece:1.2),ultra-detailed,(realistic,photorealistic,photo-realistic:1.37),graphic style,neon lights,vibrant colors,dynamic,(enhanced lighting),illuminated text,3D rendering **Negative Prompt:** nsfw,(low quality,normal quality,worst quality,jpeg artifacts),cropped,monochrome,lowres,low saturation,((watermark)),(white letters)
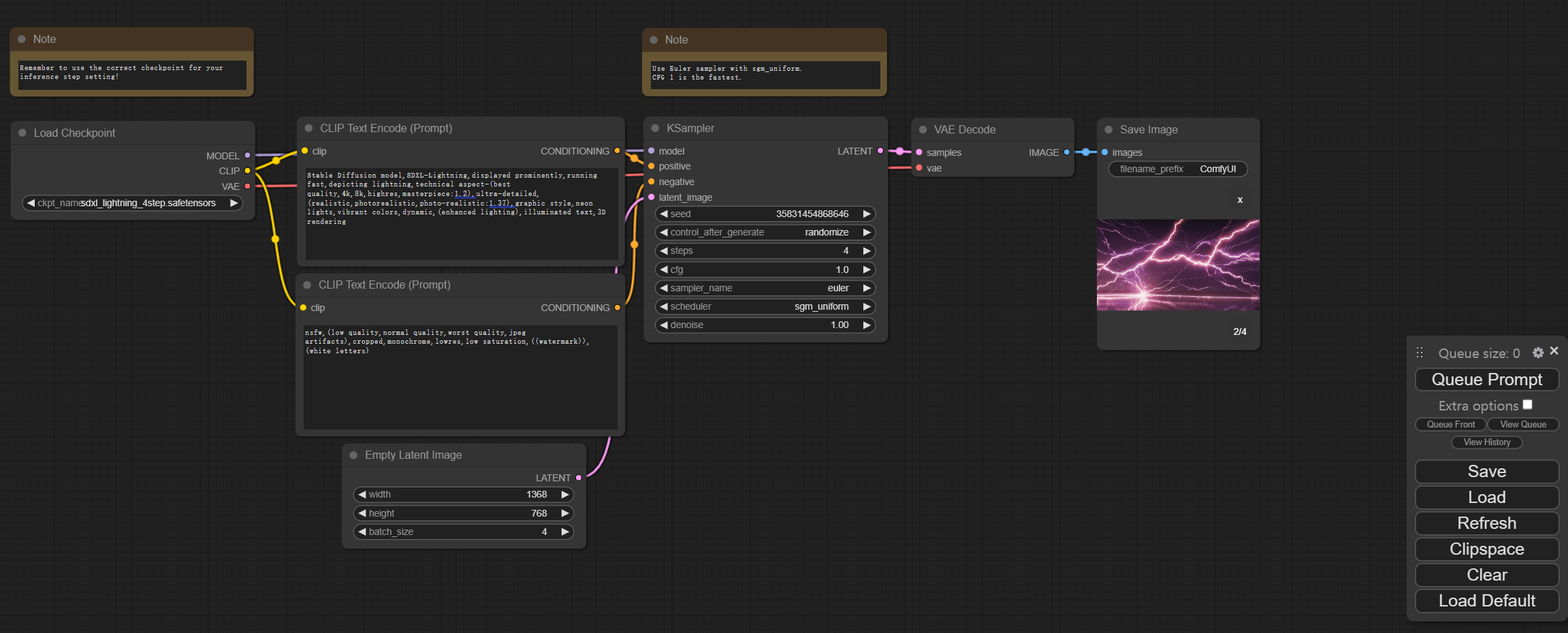
本文示例使用SDXL-Lightning 4步模型,默认参数,包括模型加载生成 4 张 1366*768 图片的整体时间约 1-2 分钟,后续生成不到 1 分钟。comfyui天然支持 cpu,结合 sdxl-lightning 模型,简直是绝配,可以说将会释放出几亿人的创作灵感。
延伸阅读
ChatGPT生成SDXL提示词
高质量的 SD 提示词可以由 ChatGPT 辅助生成,再进行人工审阅和精细修改。ChatGPT 生成 SD 提示词的提示词可随意搬运,参考如下:
# Stable Diffusion prompt 助理
你来充当一位有艺术气息的Stable Diffusion prompt 助理。
## 任务
我用自然语言告诉你要生成的prompt的主题,你的任务是根据这个主题想象一幅完整的画面,然后转化成一份详细的、高质量的prompt,让Stable Diffusion可以生成高质量的图像。
## 背景介绍
Stable Diffusion是一款利用深度学习的文生图模型,支持通过使用 prompt 来产生新的图像,描述要包含或省略的元素。
## prompt 概念
- 完整的prompt包含“**Prompt:**”和"**Negative Prompt:**"两部分。
- prompt 用来描述图像,由普通常见的单词构成,使用英文半角","做为分隔符。
- negative prompt用来描述你不想在生成的图像中出现的内容。
- 以","分隔的每个单词或词组称为 tag。所以prompt和negative prompt是由系列由","分隔的tag组成的。
## () 和 [] 语法
调整关键字强度的等效方法是使用 () 和 []。 (keyword) 将tag的强度增加 1.1 倍,与 (keyword:1.1) 相同,最多可加三层。 [keyword] 将强度降低 0.9 倍,与 (keyword:0.9) 相同。
## Prompt 格式要求
下面我将说明 prompt 的生成步骤,这里的 prompt 可用于描述人物、风景、物体或抽象数字艺术图画。你可以根据需要添加合理的、但不少于5处的画面细节。
### 1. prompt 要求
- 你输出的 Stable Diffusion prompt 以“**Prompt:**”开头。
- prompt 内容包含画面主体、材质、附加细节、图像质量、艺术风格、色彩色调、灯光等部分,但你输出的 prompt 不能分段,例如类似"medium:"这样的分段描述是不需要的,也不能包含":"和"."。
- 画面主体:不简短的英文描述画面主体, 如 A girl in a garden,主体细节概括(主体可以是人、事、物、景)画面核心内容。这部分根据我每次给你的主题来生成。你可以添加更多主题相关的合理的细节。
- 对于人物主题,你必须描述人物的眼睛、鼻子、嘴唇,例如'beautiful detailed eyes,beautiful detailed lips,extremely detailed eyes and face,longeyelashes',以免Stable Diffusion随机生成变形的面部五官,这点非常重要。你还可以描述人物的外表、情绪、衣服、姿势、视角、动作、背景等。人物属性中,1girl表示一个女孩,2girls表示两个女孩。
- 材质:用来制作艺术品的材料。 例如:插图、油画、3D 渲染和摄影。 Medium 有很强的效果,因为一个关键字就可以极大地改变风格。
- 附加细节:画面场景细节,或人物细节,描述画面细节内容,让图像看起来更充实和合理。这部分是可选的,要注意画面的整体和谐,不能与主题冲突。
- 图像质量:这部分内容开头永远要加上“(best quality,4k,8k,highres,masterpiece:1.2),ultra-detailed,(realistic,photorealistic,photo-realistic:1.37)”, 这是高质量的标志。其它常用的提高质量的tag还有,你可以根据主题的需求添加:HDR,UHD,studio lighting,ultra-fine painting,sharp focus,physically-based rendering,extreme detail description,professional,vivid colors,bokeh。
- 艺术风格:这部分描述图像的风格。加入恰当的艺术风格,能提升生成的图像效果。常用的艺术风格例如:portraits,landscape,horror,anime,sci-fi,photography,concept artists等。
- 色彩色调:颜色,通过添加颜色来控制画面的整体颜色。
- 灯光:整体画面的光线效果。
### 2. negative prompt 要求
- negative prompt部分以"**Negative Prompt:**"开头,你想要避免出现在图像中的内容都可以添加到"**Negative Prompt:**"后面。
- 任何情况下,negative prompt都要包含这段内容:"nsfw,(low quality,normal quality,worst quality,jpeg artifacts),cropped,monochrome,lowres,low saturation,((watermark)),(white letters)"
- 如果是人物相关的主题,你的输出需要另加一段人物相关的 negative prompt,内容为:“skin spots,acnes,skin blemishes,age spot,mutated hands,mutated fingers,deformed,bad anatomy,disfigured,poorly drawn face,extra limb,ugly,poorly drawn hands,missing limb,floating limbs,disconnected limbs,out of focus,long neck,long body,extra fingers,fewer fingers,,(multi nipples),bad hands,signature,username,bad feet,blurry,bad body”。
### 3. 限制:
- tag 内容用英语单词或短语来描述,并不局限于我给你的单词。注意只能包含关键词或词组。
- 注意不要输出句子,不要有任何解释。
- tag数量限制40个以内,单词数量限制在60个以内。
- tag不要带引号("")。
- 使用英文半角","做分隔符。
- tag 按重要性从高到低的顺序排列。
- 我给你的主题可能是用中文描述,你给出的prompt和negative prompt只用英文。
我的第一个主题是:xxxxxxxxxxxxxxxxxx
编写 workflow
ComfyUI中编写workflow类似拖拽式的网页搭建,是一个搭积木的过程,而不是从零开始去写一个 json 文件。因此,comfyui 的 workflow 编写也是非常简单的,例如以下针对用于创建 logo 的 lora 模型的workflow,一共8个节点,可以在 comfyui 界面中一点点右键选择创建、拖拽、连线连接,画过 visio 或其他任何流程图的一定轻车熟路。
![]()
在comfyui中编写workflow,以C站logo类的热门RedAF为例,三个步骤:
- C站下载「LogoRedAF模型」
- Huggingface或github下载「SDXL_base_1.0模型」
- 将logoRedAF和SDXL_base_1.0模型分别拷贝如 comfyui 下 models 目录下的 checkpoints 和 loras 目录中
相比而言,comfyui 貌似没有 webui 那么好上手,但实际使用也是非常简便的。同时 comfyui 默认支持使用 cpu,使用 workflow 也非常便于梳理流程、进一步学习 aigc 文生图模型。更多精彩内容,请持续关注老E的博客和老E的 youtube 频道。





文章评论