







ChatTTS 是一个开源自然语言处理项目,可以生成自然流畅的语音输出。其训练数据涵盖了大量中英文语料库,包括丰富的对话场景和语境信息,使模型能够生成逼真、自然的语音。更重要的是,chattts 支持对笑声、停顿和插入词等声音元素的控制,使得生成的语音更加生动真实。开源以来,持续火爆。毫无疑问,ChatTTS 是目前最好的文本转语音项目,但对新手而言,由于其版本和 API 的迭代,本地化部署一直存在不低的门槛。本文主要讲解在 windows 11 虚拟环境下本地化部署 ChatTTS 的方法和过程,以 conda 为主。由于 python venv 环境无法在 windows 下顺利编译 pynini,也无法在 venv 环境下通过 conda forge 安装预编译的 pynini 包,适合不需要归一化处理的应用。
Git 拉取项目、下载模型甚至安装 python 包,都离不开稳定的网络环境,有需要的可注册订阅「LH机场」。如果需要一个干净的整合包,可以采用本文随附的整合包,仅包含必须依赖、模型和一个示例 example.py文件,下载点击『此处』。
前备条件
ChatTTS 本地部署原生为 linux 平台,且迭代较快,很多时候,小伙伴会发现项目主页的示例脚本不做修改无法运行。本文列举的部署方法和过程,在满足以下前备条件的前提下,是肯定可以成功的。
- 使用 conda 在虚拟环境下部署,需要安装 anoconda 或 miniconda
- python 版本建议不高于 3.12.1
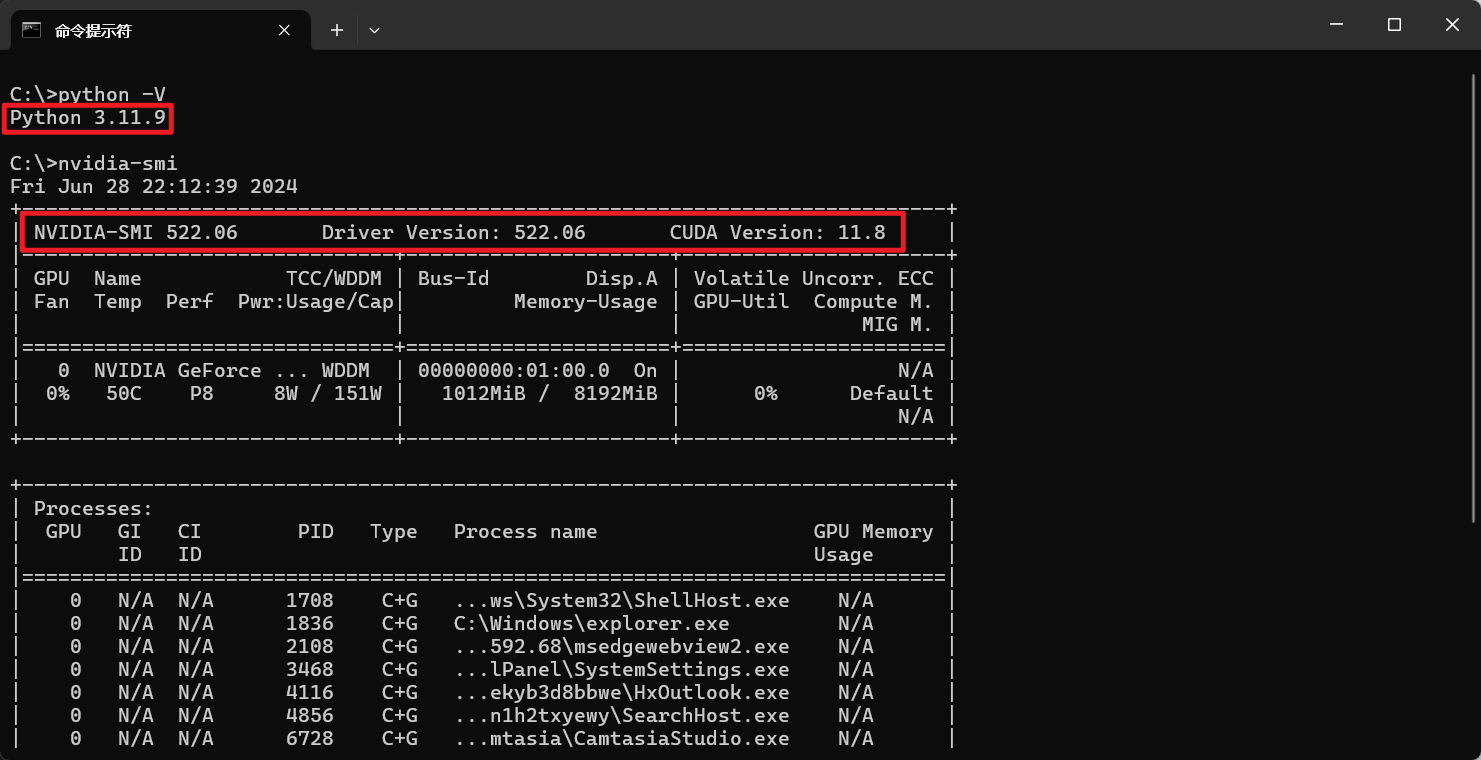
- ChatTTS 支持 CPU,如需使用 GPU,需安装适配版本的 cuda 和 cudnn ,且显存不少于 4GB,cuda 版本建议为 11.8
- 稳定的网络环境
克隆代码仓库
git clone https://github.com/2noise/ChatTTS cd ChatTTS
创建并激活虚拟环境
在 ChatTTS 目录下创建 venv 目录,并指定以此目录创建 conda 虚拟环境。激活该环境后,后续所有命令在此环境下执行。
mkdir venv conda create --prefix=X:\your_project_path\venv python=3.11 conda activate X:\your_project_path\venv
删除通过指定目录创建的虚拟环境应使用以下命令。
conda remove -p X:\your_project_path\venv --all
安装依赖
需要注意的是 pynini 务必选择 2.1.5 预编译版本,nemo_text_processing 和 WeTextProcessing 依赖于 2.1.5 版本,而非最新的 2.1.6 版本。如需使用 GPU 加速,在「pytorch 官网」,获取正确的安装命令,pip3 可替换为 pip、torchvision 可剔除,并注意示例的 cuda 版本为 11.8,如不同务必自行替换。
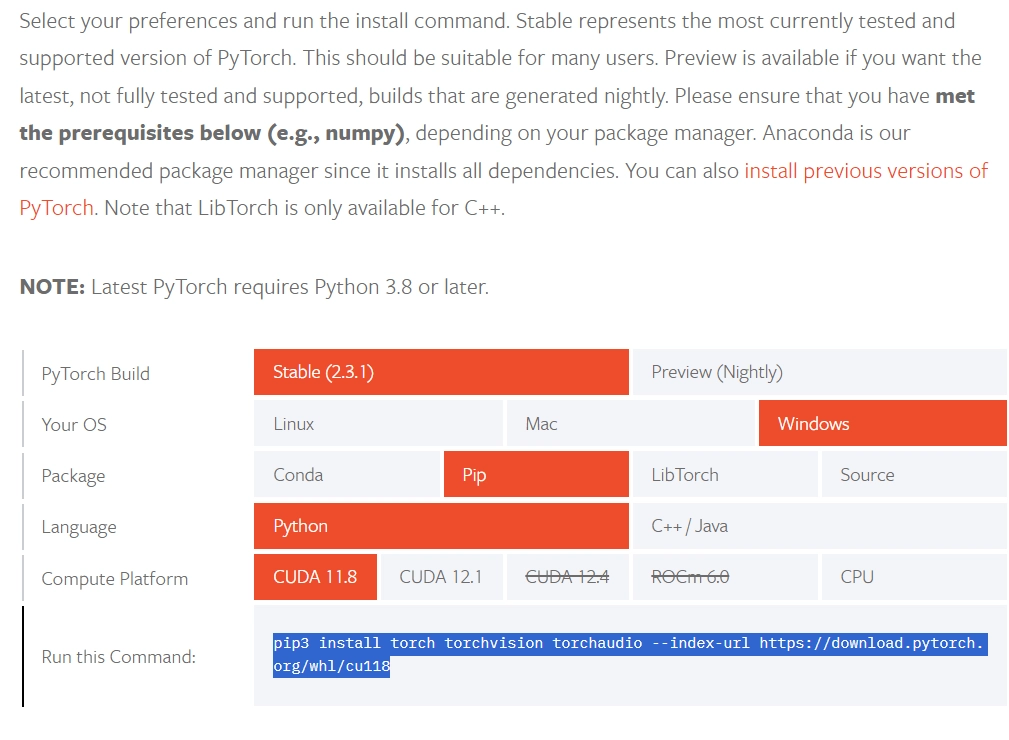
pip install -r requirements.txt .\venv\python.exe -m pip install --upgrade pip setuptools wheel conda install -c conda-forge pynini=2.1.5 && pip install nemo_text_processing WeTextProcessing pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118 # 仅CPU忽略--index-url及其后所有内容
需要使用 jupyter notebook 运行的,还需安装 jupyter。
pip install jupyter jupyter notebook --notebook-dir=X:\your_project_path
VENV虚拟环境部署ChatTTS
同样,通过 python 自带的 venv,我们也可以创建虚拟环境、本地部署 chattts并制作整合包,依赖的安装都是在虚拟环境下进行的。ffmpeg 等后端音视频处理工具自行安装并配置好环境变量,否则运行会报错。
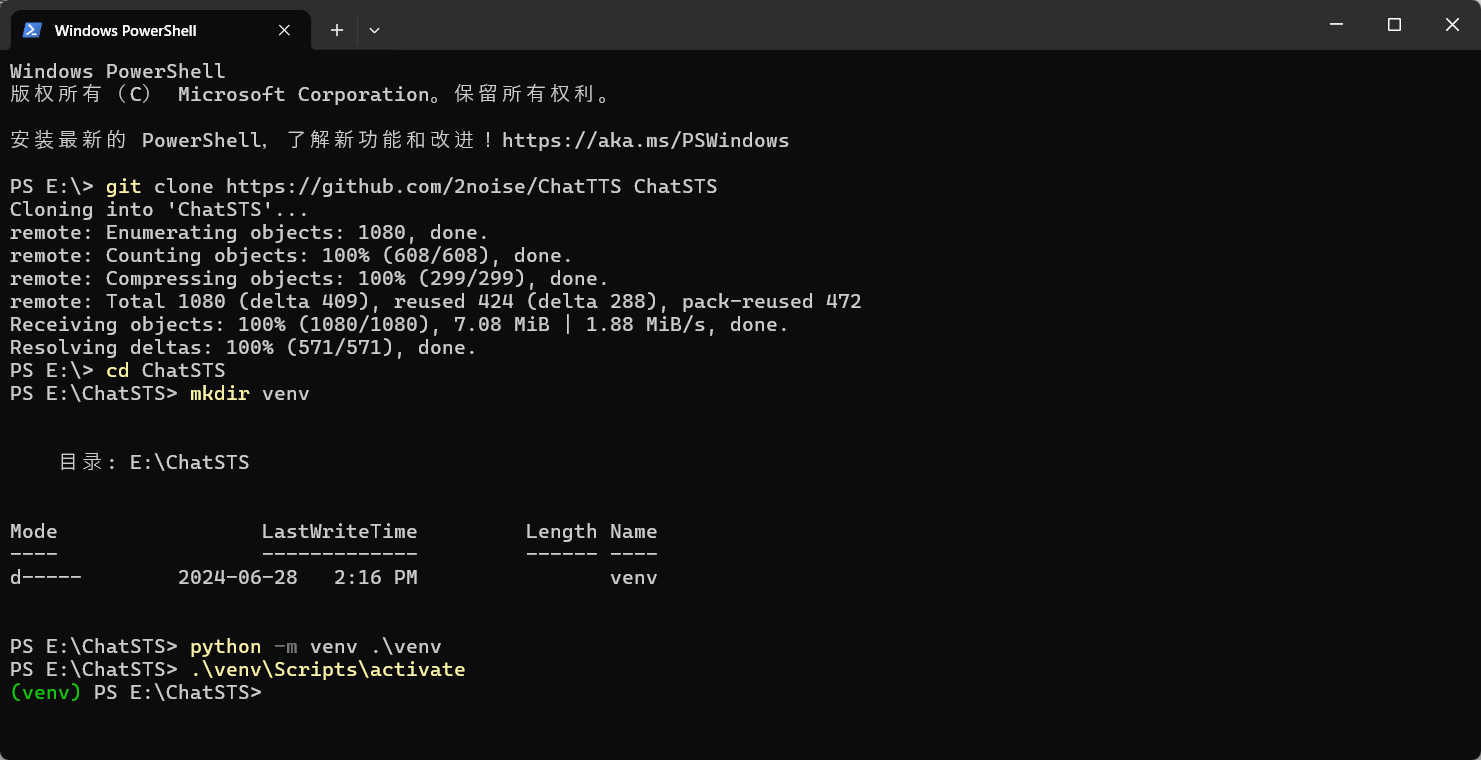
git clone https://github.com/2noise/ChatTTS ChatSTS cd ChatSTS mkdir venv python -m venv .\venv .\venv\Scripts\activate pip install -r requirements.txt pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118 pip install pysoundfile @python.exe -m pip install --upgrade pip @可按照提示更新pip
之后,我们可以在 ChatSTS 目录(注意不是 ChatTTS 子目录)下创建 python 脚本文件example.py。
import torch
import torchaudio
import ChatTTS
from IPython.display import Audio
# 初始化ChatTTS
chat = ChatTTS.Chat()
chat.load(
#使用CPU务必删除下一行设备指定cuda
device="cuda",
compile = False,
)
# 定义需要转音频的文字内容
texts = ["Hi,大家好 欢迎来到老E的频道,without answer,我的微信公众号是智能生活引擎。专注于互联网、人工智能等技术应用领域,欢迎订阅、关注",]
# 生成音频
wavs = chat.infer(texts, use_decoder=True)
import os
dirs = "output"
if not os.path.exists(dirs):
os.makedirs(dirs)
# 保存音频文件到本地文件(采样率为24000Hz)
torchaudio.save(".\output\output-01.wav", torch.from_numpy(wavs[0]), 24000)
# 播放音频
Audio(wavs[0], rate=24_000, autoplay=True)
激活虚拟环境后运行 example.py 脚本,首次运行会自动从 hugging face 下载模型。
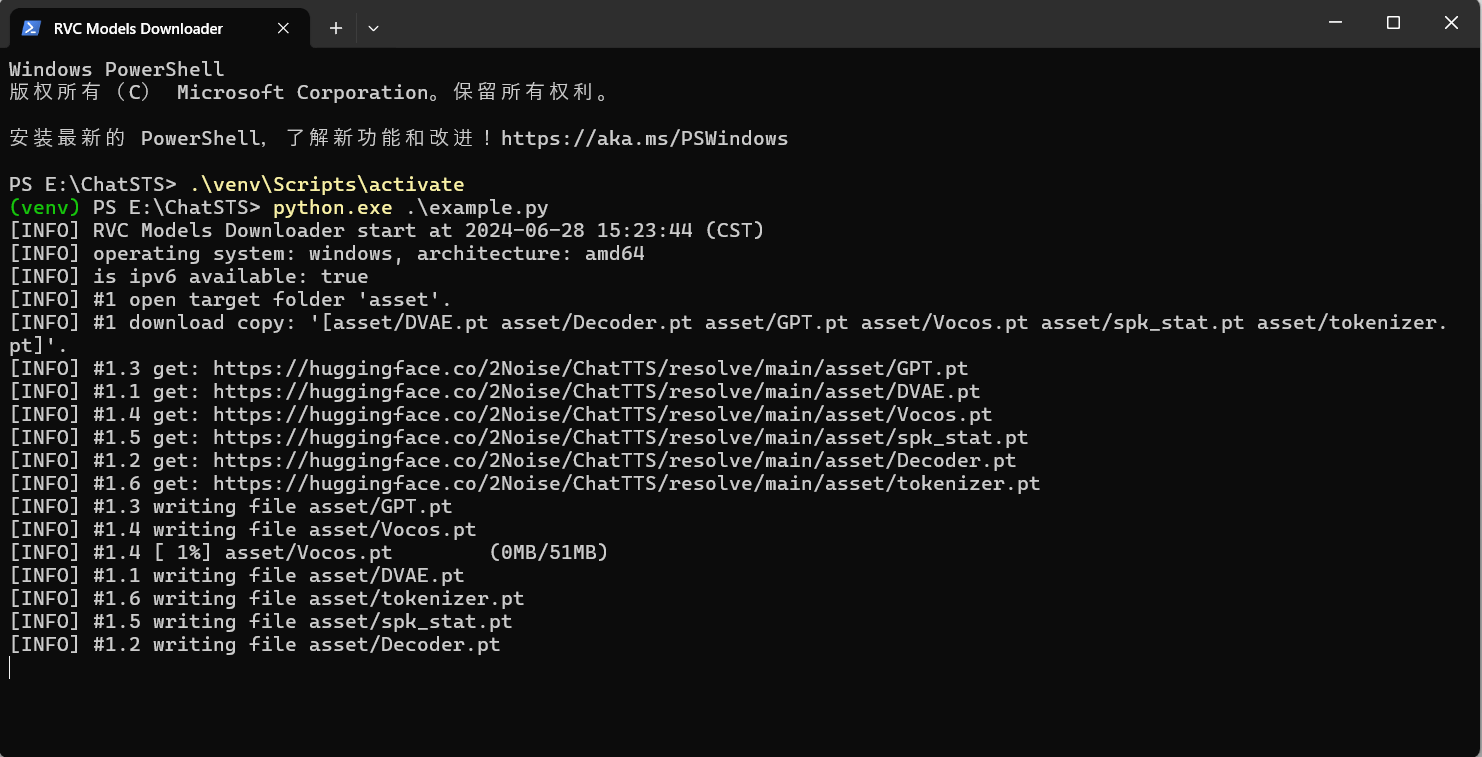
.\venv\Scripts\activate python.exe example.py
example.py 仅仅提供了一个针对当前版本 ChatTTS 可用的示例,在此基础上可以向 ChatGPT 提问,逐步构建完成你期望的应用。包含所有模型的最小整合包,可通过关注公众号『智能生活引擎』后,发送关键词『ChatTTS』获取直链下载链接。
更多精彩,敬请关注老E的博客!





文章评论