







Ragflow 看似“简陋”的工作流编排界面,实际上具有为处理复杂的 RAG 工作流量身定制的特性,与其他试图涵盖太多功能但效率偏低的通用工shiji具/框架不同,Ragflow 专注于为检索和 AI 生成管道(pipeline)提供基础支撑。这体现在 RAGFlow 工作流并没有单独的 “LLM” 组件,但在所有涉及 LLM 的工作流组件中,都包含了指定 LLM 的必选配置。
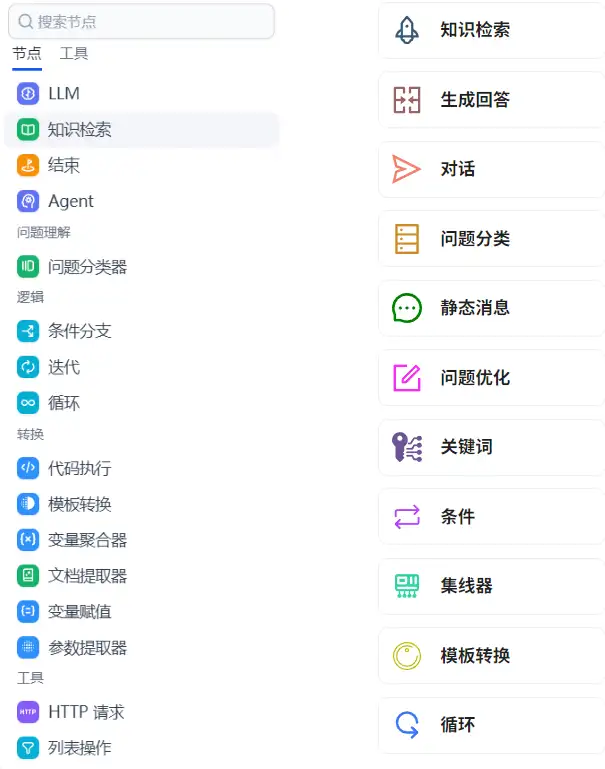
工作流组件(节点)
- Begin(开始)组件
- 启动工作流:Begin组件是工作流中的起始组件,自动出现在画布上,不能被删除。
- 设置开场白或接受输入:可以设置开场白或接受用户输入的全局变量。
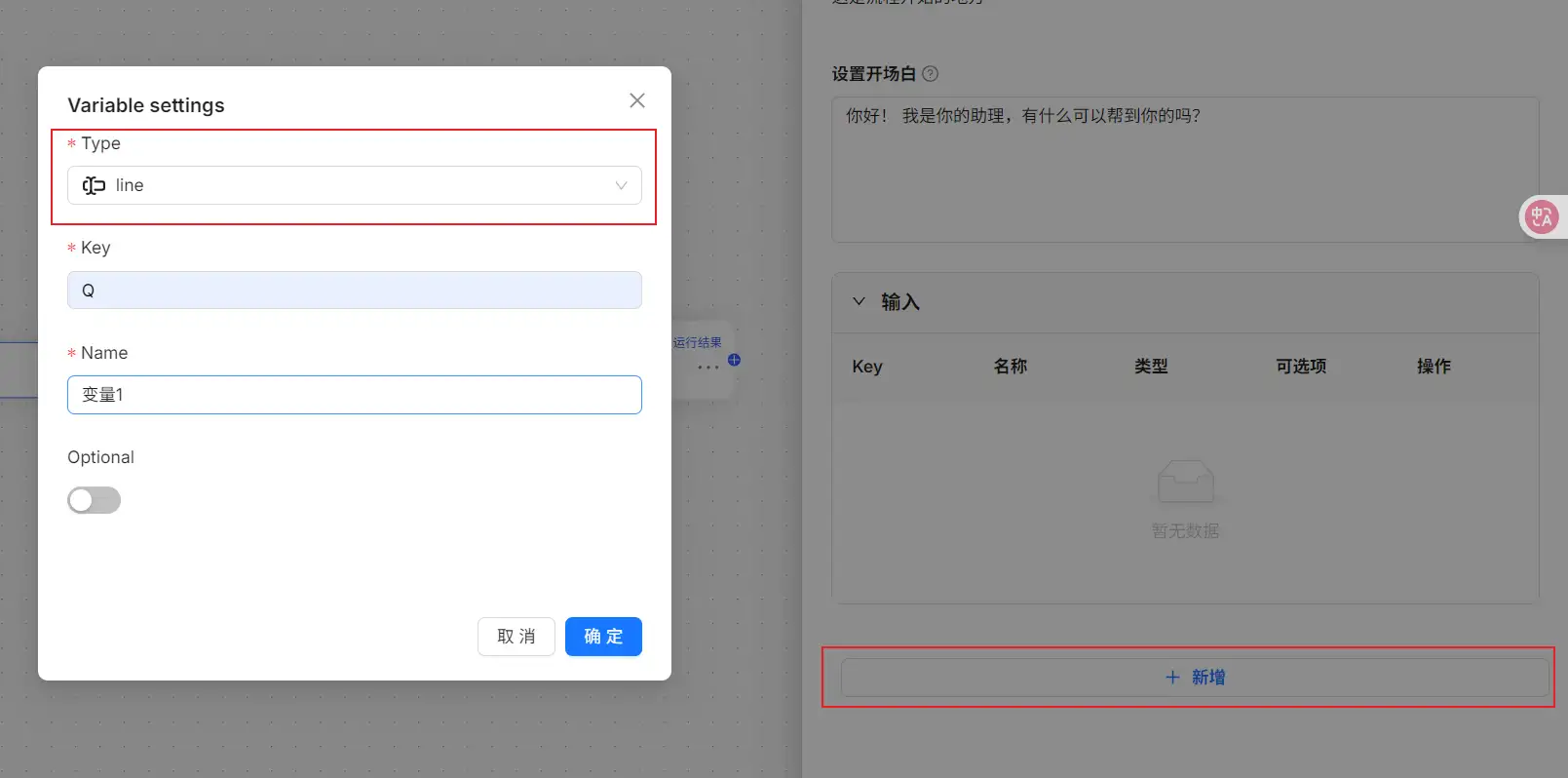
在开始节点中,我们可以设置 agent 的开场白,通过点击『新增变量』(需要注意的是,ragflow的变量是全局变量),在变量设置对话框,可以通过设置变量类型。
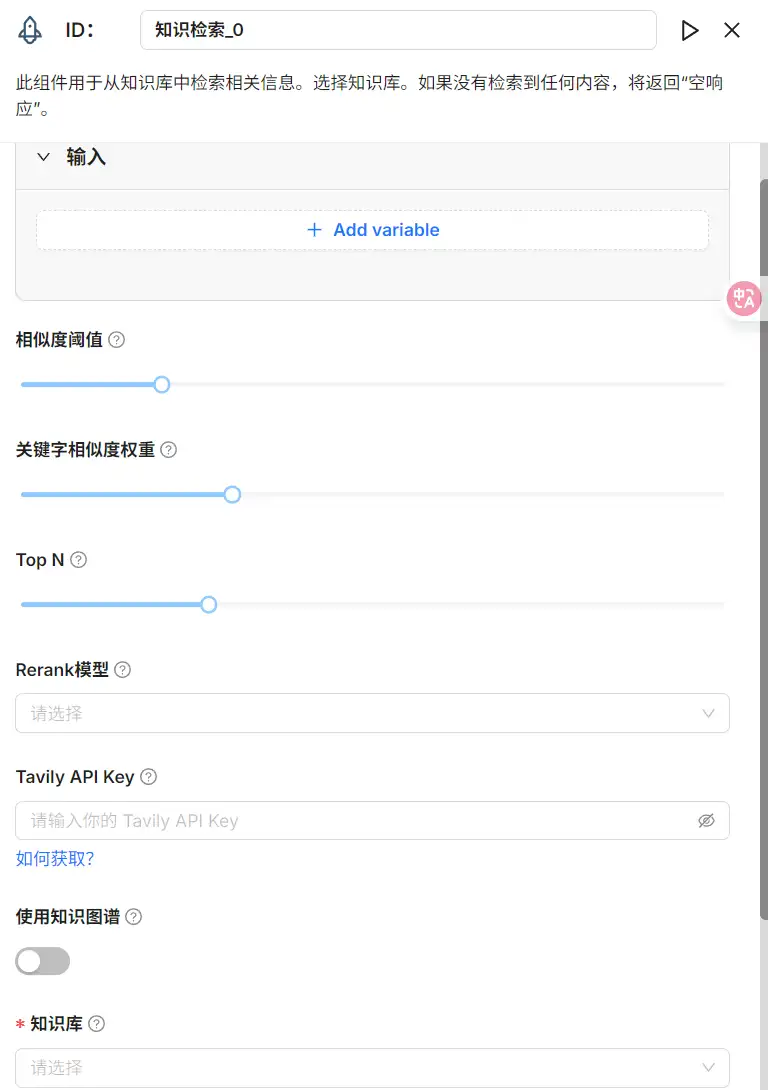
- Retrieval(知识检索)组件
此组件用于从知识库中检索相关信息。选择知识库。如果没有检索到任何内容,将返回“空响应”。
-
- 新增输入变量:两种类型的输入变量——引用和文本。引用使用组件输出或用户输入作为数据源,Text 使用固定文本作为查询。
- 相似度阈值:设置用户查询与数据集中存储的块之间的相似度阈值,默认值为 0.2。
- 关键词相似度权重:设置关键词相似度在综合相似度得分中的权重,默认值为 0.7,向量相似度的权重为 0.3。
- Top N:从检索到的块中选择“Top N”块并传递给 LLM,默认值为 8。
- 重排模型:可选,如果选择了重排模型,将使用加权关键词相似度和加权重排得分进行检索,但这会显著增加系统的响应时间。
- 知识库:可以选择多个知识库,如果选择多个,必须保证它们使用相同的嵌入模型,否则会出现错误信息。
- 空回复:如果没有检索到数据,回复设置的默认值。
- Generate(生成回答)组件
此组件用于调用 LLM 生成文本,应注意提示词设置。
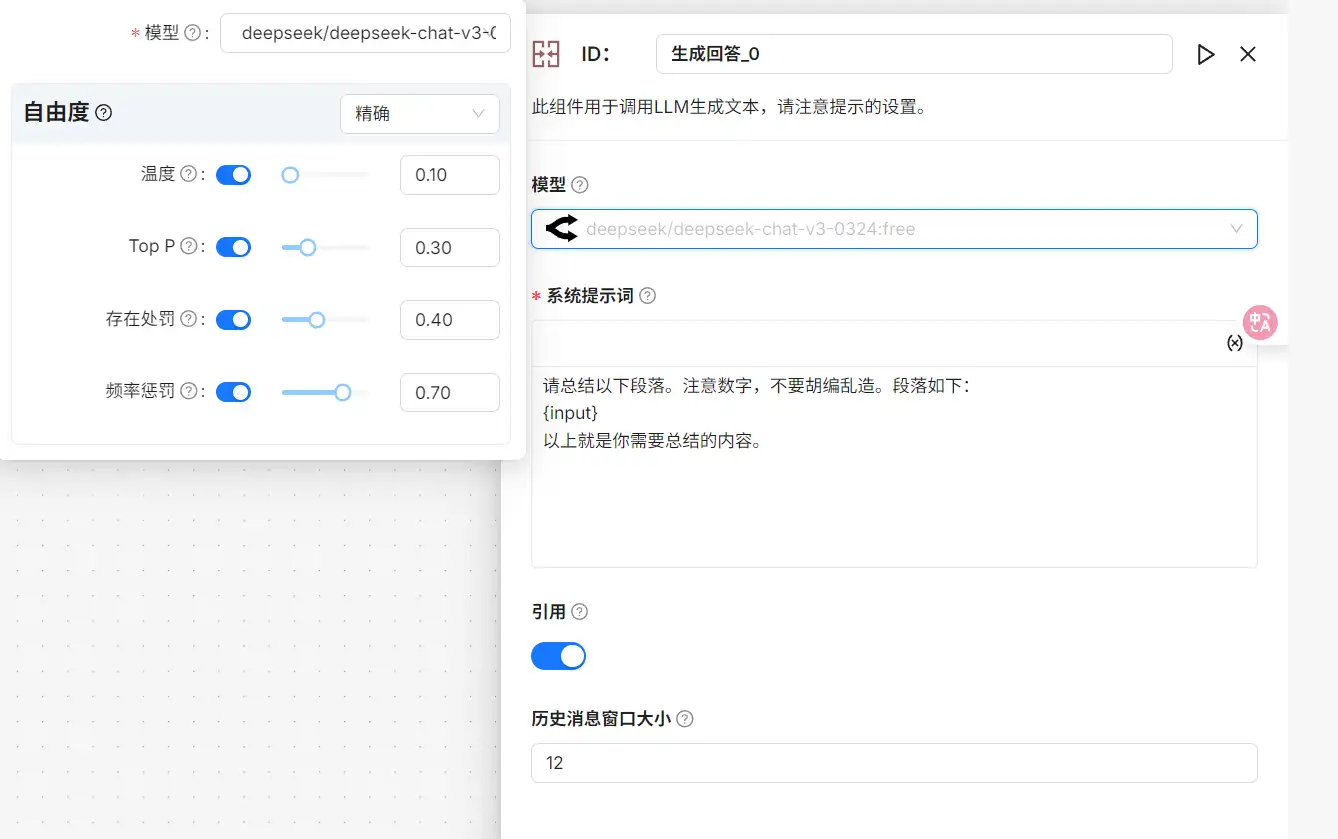
-
- 在生成回答组件中,可以修改修改组件的 id
- 可以调整组件使用的模型,可以选择已经配置的模型服务以及温度、Top P、存在处罚、频率处罚等参数配置
- 引用,主要用于多轮会话,是否引用以前的内容
- 在前序节点新增变量以后,才可以在组件内使用
- Interact(对话)组件
该组件用作机器人与人类之间的接口。它接收用户的输入并显示机器人的计算结果。
- Categorize(问题分类)组件
此组件用于对文本进行分类。请指定类别的名称、描述和示例。每个类别都指向不同的下游组件。问题分类,你可以理解为是条件判断的增强,条件判断是基于具体的值,问题分类是使用大模型根据问题描述,以及示例,推导出的分类,并指向对应的流程。
- Message (静态消息)组件
该组件用于向用户发送静态信息。您可以准备几条消息,这些消息将被随机选择。
- Rewrite(问题优化)组件
该组件用于细化用户的提问。通常,当用户的原始提问无法从知识库中检索到相关信息时,此组件可帮助您将问题更改为更符合知识库表达方式的适当问题。
- keyword( 关键词 )组件
该组件用于从用户的问题中提取关键词。Top N指定需要提取的关键词数量。比如用于我们之前的从数据库查询知识的场景,不用我们去处理了。
- Switch(条件)组件
该组件用于根据前面组件的输出评估条件,并相应地引导执行流程。通过定义各种情况并指定操作,或在不满足条件时采取默认操作,实现复杂的分支逻辑。
- Concentrator(集线器)组件
该组件可用于连接多个下游组件。它接收来自上游组件的输入并将其传递给每个下游组件。
- Template(模板转换)组件
该组件用于排版各种组件的输出。有助于将各种数据或信息源组织成特定格式,便于后续处理和展示。
- Loop(循环)组件
该组件首先将输入以“分隔符”分割成数组,然后依次对数组中的元素执行相同的操作步骤,直到输出所有结果,可以理解为一个任务批处理器。 例如在长文本翻译迭代节点中,如果所有内容都输入到LLM 节点,可能会达到单次对话的限制,上游节点可以先将长文本分割成多个片段,配合迭代节点对每个片段进行批量翻译,避免达到单次对话的 LLM 消息限制。
除了上面列出的基础组件外,RAGFlow 还提供了工具/高级应用组件,工具/高级应用组件主要是封装了一些 LLM 能力,以实际应用为主,从实际使用效果来看:聊胜于无。
示例工作流
图示工作流是不可运行的,因为缺少对“其他问题”的分类输出处理。参考「视频」,可直接将“其他问题”输出提交“生成回答”节点进行处理,以便进行测试。示例工作流并不符合 RAG 基本范式,但在很多知识库不健全或者没有知识库支持、希望利用 LLM 能力提升体验甚至销售业绩的场景下,RAG 范式“不重要”。
另外,对于实现问答类的工作流,RAGFlow 需要手动连接最后的生成回答节点和入口对话节点,构建回环以匹配多轮对话需求,而不是工作一次就结束、需要重新调用拉起。对于工作流编排来说,从设计上来看,确实有大量的实际业务需求都是一次性的,例如报告生成、文档解析等,即便私有化部署的系统,多数情况下都不需要持续“循环”提供服务。
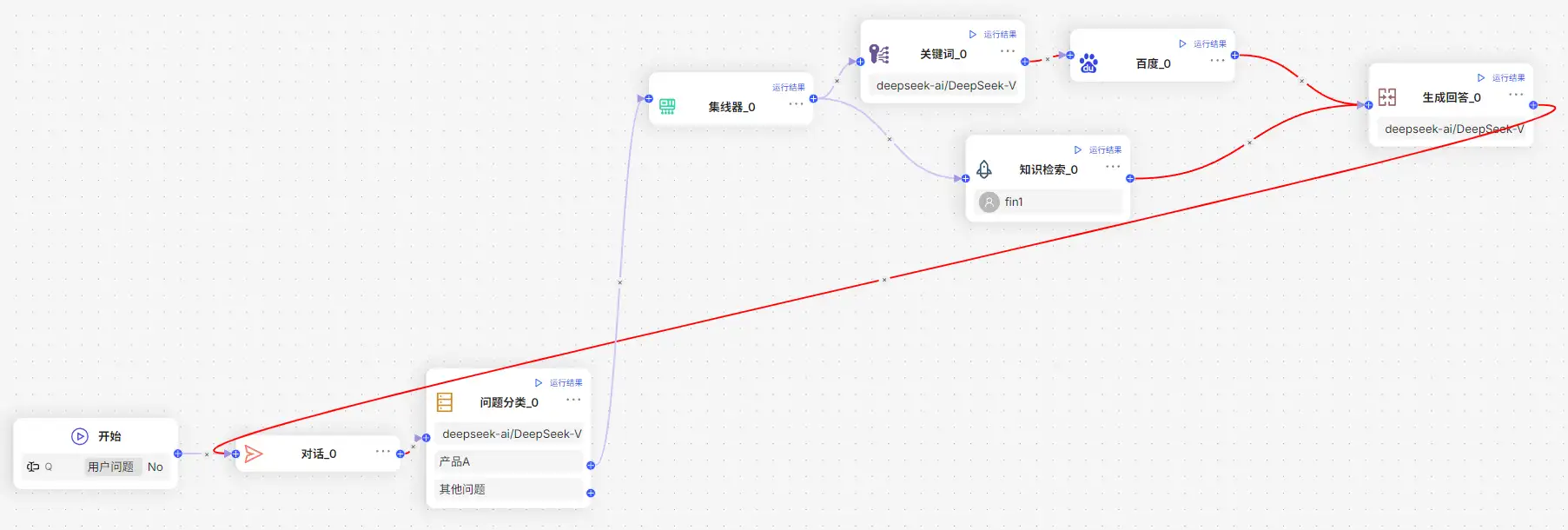
对于智能问答的智能客服领域,假定有 A、B、C 三个独立领域,可以根据领域对用户问题进行分类。对于每一个领域,匹配独立的处理流程,如实例中的知识库检索+联网搜索相结合进行回答。主要节点包括:
- 开始节点:定义了名称为“用户问题”的全局变量,供后续节点引用
- 问题分类节点:调用 LLM 对“用户问题”进行分析、归类
- 关键词节点:对用户问题提取搜索关键词
发布工作流
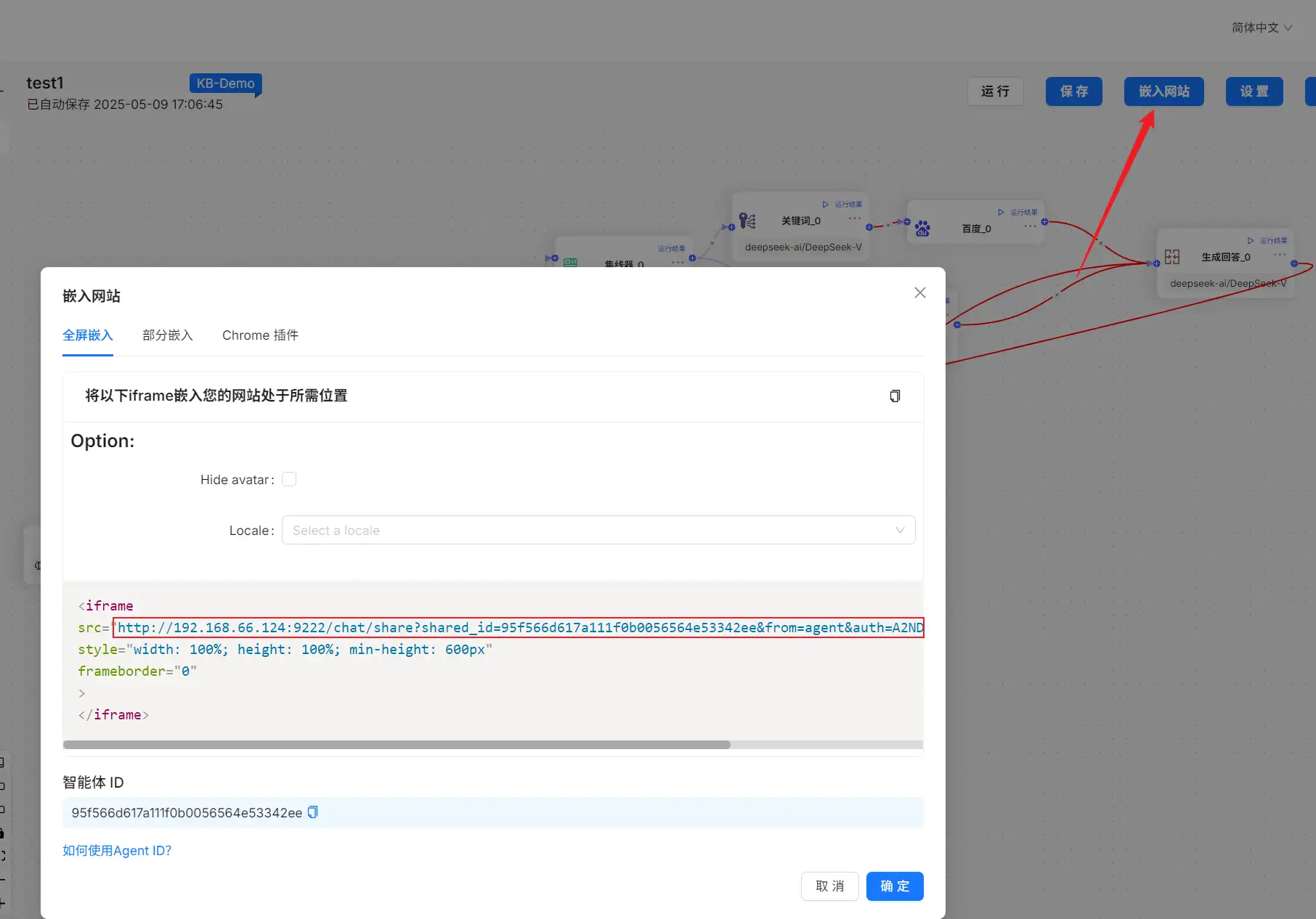
和其他平台的工作流编排发布相同,RAGFlow 中可以点击上方的『嵌入网站』进行发布。在嵌入网站页面,可以看到 iframe 嵌入代码,以及『智能体 ID』。如果不是简单的嵌入网站,而是在前端项目中集成工作流调用,参考官方文档引用该智能体 ID 即可。iFrame 中的代码,src 属性的 url 可以直接拷贝、粘贴使用。
对于很多需要进行数据库查询的业务,如用户问题涉及下单,一般需要添加 exeSQL 工具节点,在查询存量、确认是否购买、获取用户信息后,才能构造下单请求,在新标签页中打开购买页面。当然,结合 Playwright 或 Selenium 等框架(MCP 服务),可以实现自动填单、付款等,但前提是必须取得用户许可,而不是流氓操作。
更多精彩,敬请关注「老E的博客」!





文章评论