







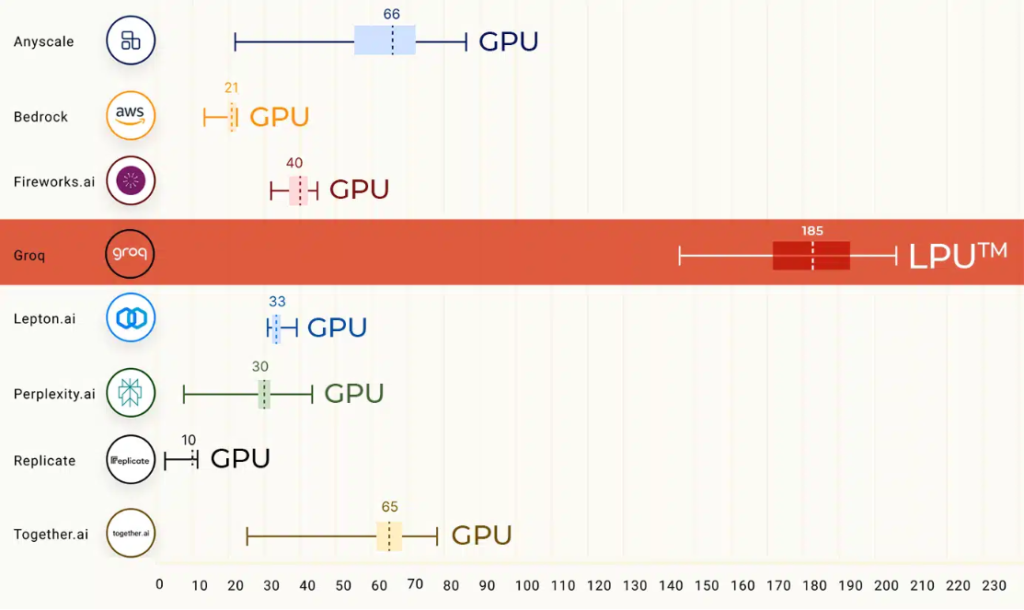
近日,groq 火爆出圈。Groq平台采用 Mixtral 8x7B-32k 模型可以实现每秒生成 500 个 tokens,GPT-4 (基于 GPU)一般情况下是每秒40 tokens,更是比 GPT-3.5 快 18 倍,自研LPU(Language Processing Units)推理速度是英伟达 GPU 的10倍。

需要强调的是,Groq 并没有研发新模型,它只是一个模型启动器,运行的是开源模型Mixtral 8x7B-32k 和 Llama 270B-4k。所以,结论一是 groq 超越 ChatGPT 是个伪命题。
为什么这么快?
出圈的响应速度,来自驱动模型的硬件——平台并未使用英伟达的GPU,而是自研了新型AI芯片——LPU(Language Processing Units)。
Groq (不要与埃隆·马斯克创立的 Grok 混淆 )是一家创建专为运行 AI 语言模型而设计的定制硬件的公司,其使命是提供更快的 AI——准确地说,比普通人打字的速度快 75 倍,该公司专门为AI和高性能计算应用程序开发高性能处理器和软件解决方案。

GroqCard™ Accelerator 售价 19,948 美元,可供消费者随时使用,是这项创新的核心。从技术上讲,它拥有高达 750 TOP (INT8) 和 188 TFLOPs (FP16 @900 MHz) 的性能,以及每芯片 230 MB 的 SRAM 和高达 80 TB/s 的片上内存带宽,优于传统的 CPU 和 GPU 设置,特别是在 LLM 任务中。这种性能飞跃归因于 LPU 能够显著减少每个 Token 的计算时间并缓解外部内存瓶颈,从而实现更快的文本序列生成。
将 LPU 卡和NVIDIA 的旗舰 A100 GPU 进行比较的话,成本相似,GroqCard™ 在处理大量简单数据 (INT8)等重要的任务中的速度和效率表现更出色。但是,在处理需要更高精度的更复杂的数据处理任务 (FP16) 时,Groq LPU 无法达到 A100 的性能水平。从本质上讲,这两块卡在 AI 和 深度学习计算的不同方面总体都表现出色,Groq LPU 卡在快速运行 LLMs 方面具有极强的竞争力,而 A100 则在其他地方处于领先地位。Groq 将 LPU 定位为运行 LLM 的工具,而不是原始计算或微调模型。
所以,结论二是 groq 和 nvidia 各有千秋。
如何使用?
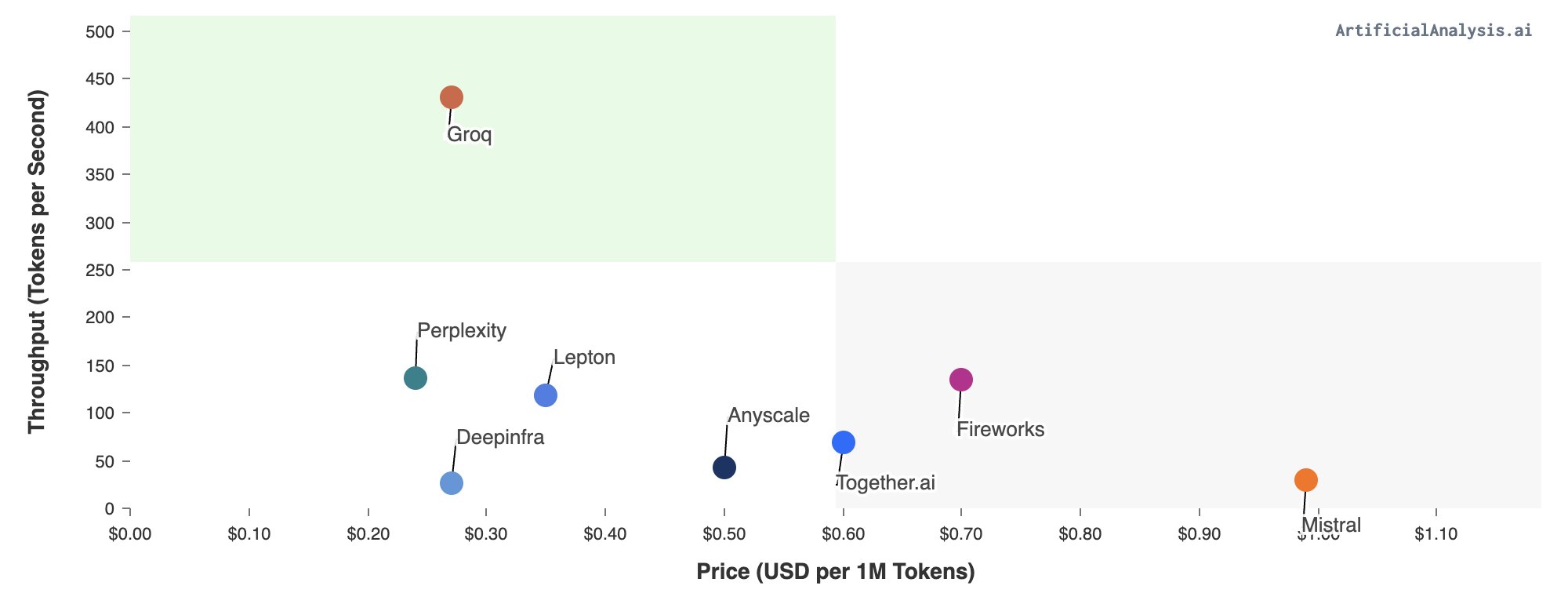
不仅快、而且便宜
目前 API 已向开发者提供,并且完全兼容OpenAI API。 点击「这里」可以了解 “wow” 详细信息,直接访问其对话页面可以点「这里」。Mixtral 8x7B SMoE可以达到480 token/S,100万token价格为0.27美元。极限情况下,用Llama2 7B甚至能实现750 token/S。

而对于每M tokens的平均价格,官方也给出了对比。
免费试用
当前 API 可以免费试用 10 天。因为兼容 OpenAI API,因此一般的 ChatGPT 非官方客户端都可以直接使用。当然,建议直接在其网页端试用:
模型默认为Mixtral 8x7B-32k,可选 Llama 2 70B-4k。不用注册就可体验,真的很快,以下图片生成部分真实还原、未作加速,每秒直冲 525 tokens。
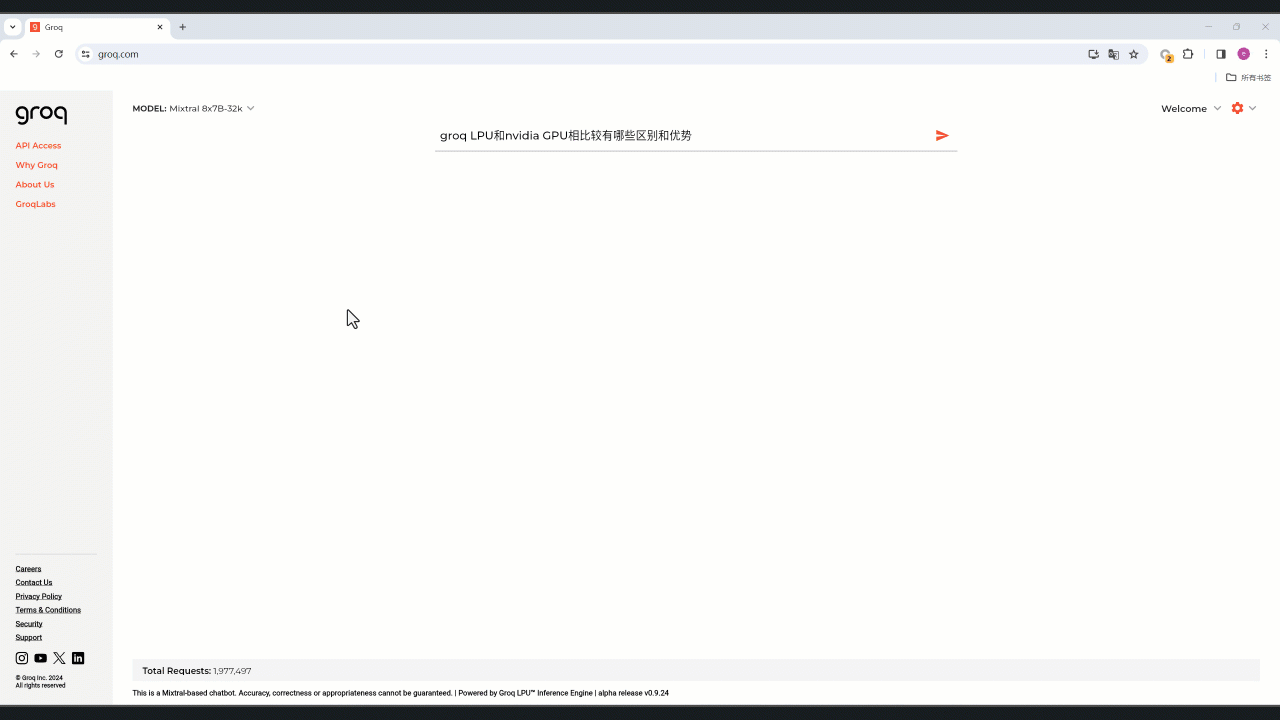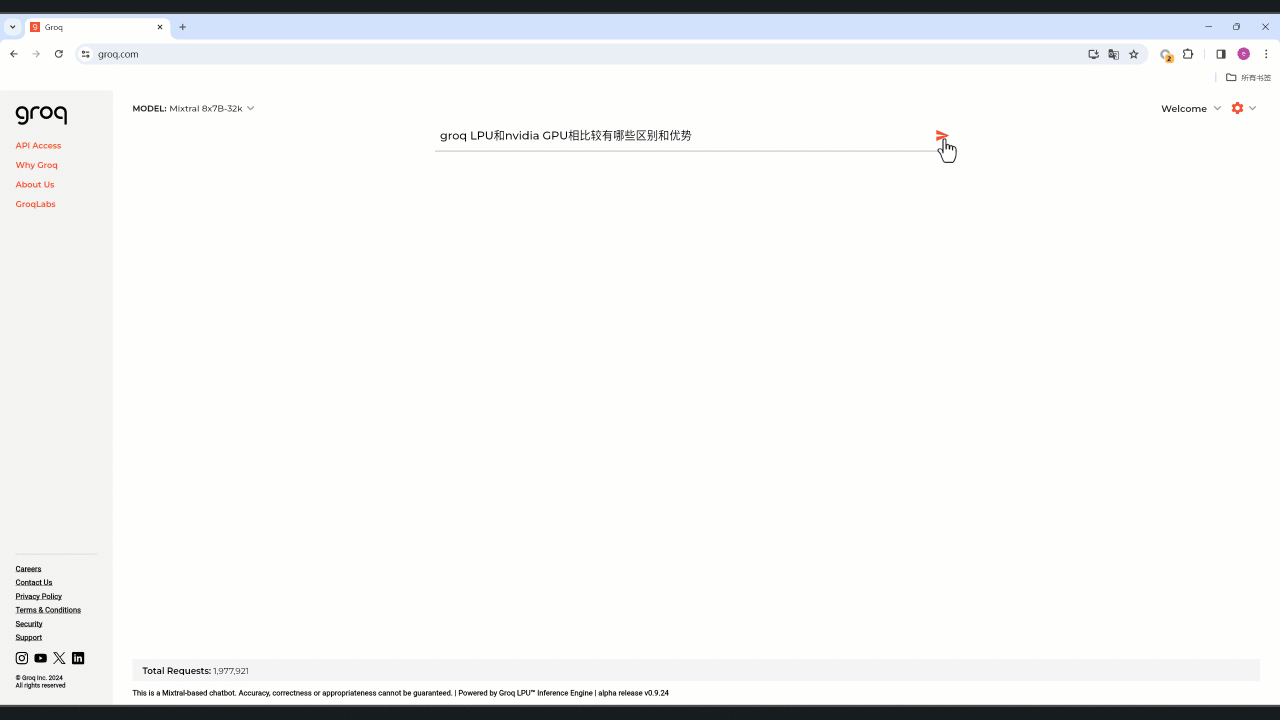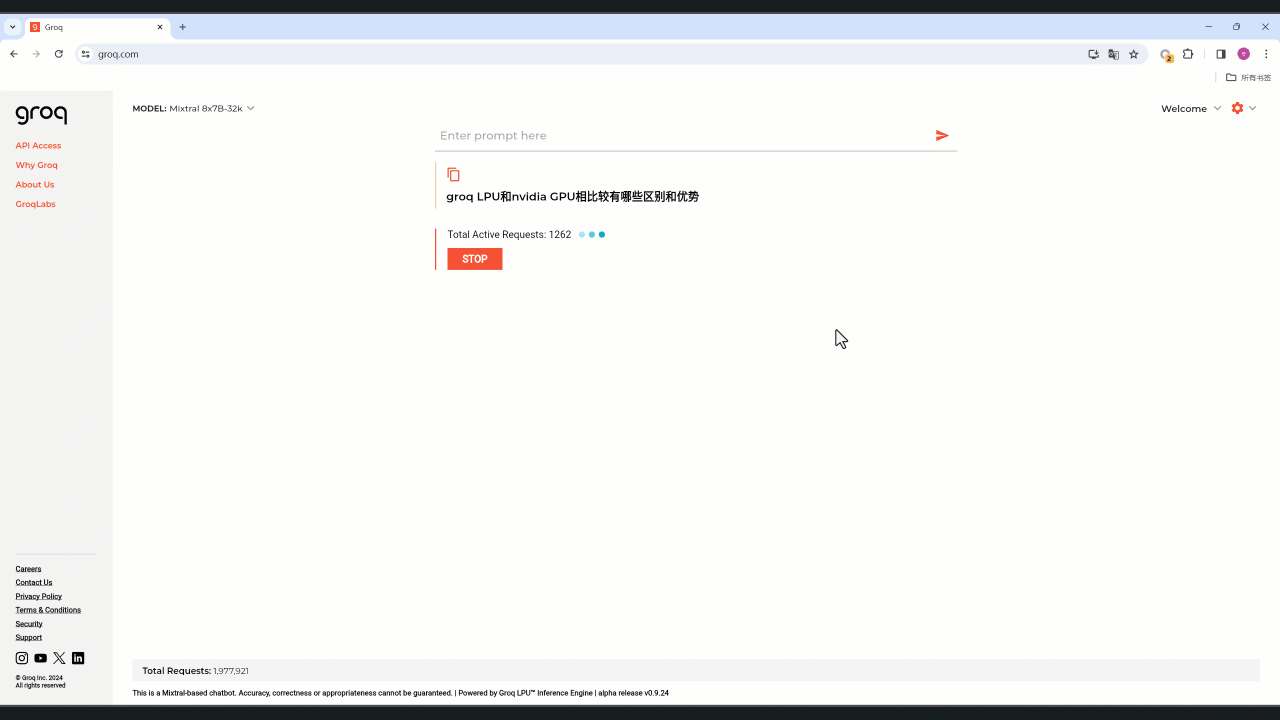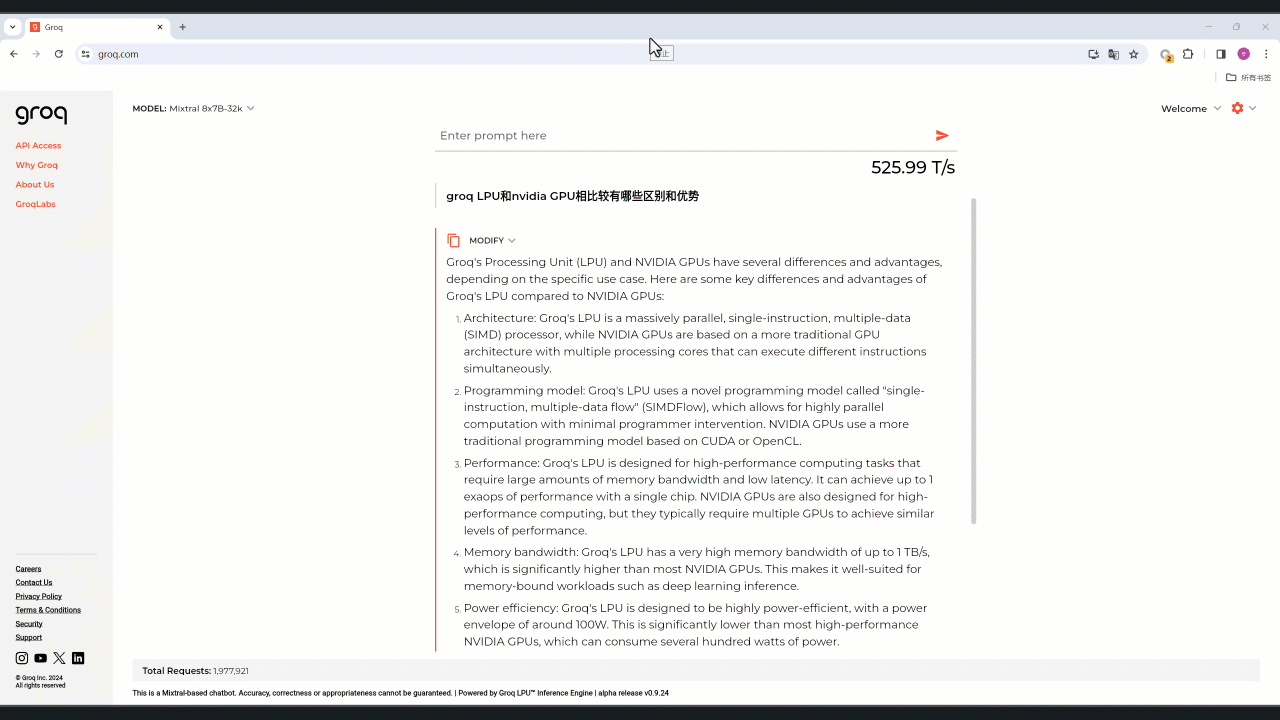
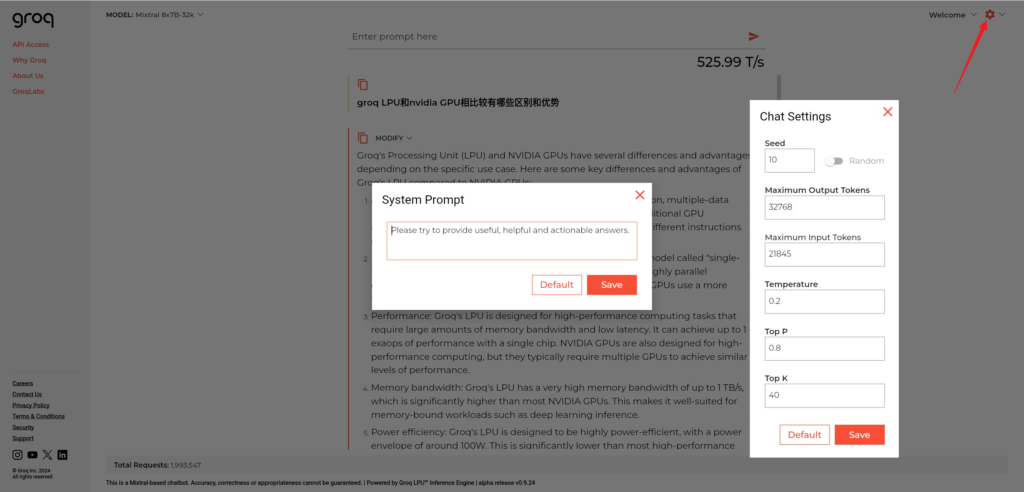
可以对系统提示词(System Prompt)比如角色设定等进行设置,同时可以设置输入输出token、发散度(温度)等。
目前,groq 可以直接访问匿名体验,非常友好。如果注册、登录的话则需要魔法,因为依赖于 google 账号。速度快不代表质量高,不想花钱的可以结合往期博文「人人都可免费本地使用GPT4」,对比文本对话输出的质量。
作为一家由多位前 Google TPU 开发者组建的芯片公司,groq 一经成立便备受关注。2016年底,曾领导研发 Google 张量处理单元(TPU,用于加速机器学习而定制的芯片)的Jonathon Ross离职创办了groq,他们希望能为 AI 和 HPC 工作负载提供毫不妥协的低延迟和高性能。从近期火出圈的效果来看,貌似是做到了。





文章评论